Scaling Applications with Google Cloud’s Auto-Scaling Features: A Developer’s Guide
- Ashish Tiwari
- Oct 20, 2024
- 5 min read
Updated: Oct 21, 2024
In today’s fast-paced digital landscape, ensuring that your applications can handle variable traffic loads is crucial. Whether it's an e-commerce platform experiencing a surge of users during Black Friday or a social media app handling sudden viral trends, scalability is key to maintaining performance and minimizing costs. Google Cloud’s Auto-Scaling features empower developers to create dynamic and responsive systems that automatically adjust resources based on real-time demand.
In this guide, we’ll walk you through the essentials of Google Cloud Auto-Scaling, explaining how to leverage it for scalable applications while showcasing real-time case studies and architecture diagrams for clarity.
Table of Contents
Introduction to Auto-Scaling
Types of Auto-Scaling in Google Cloud
Setting Up Compute Engine Auto-Scaling
Kubernetes Auto-Scaling with Google Kubernetes Engine (GKE)
Real-Time Case Study: Scaling a Web Application
Best Practices for Using Google Cloud Auto-Scaling
Monitoring and Alerts: Staying in Control
Conclusion and Next Steps
1. Introduction to Auto-Scaling
Auto-scaling is the process by which cloud resources are automatically adjusted (scaled up or down) based on the application’s traffic. This ensures that:
● You are charged only for the resources you utilize.
● Your applications remain responsive even under high demand.
● System failures due to resource exhaustion are minimized.
In Google Cloud, auto-scaling can be applied to Compute Engine, Google Kubernetes Engine (GKE), and Cloud Functions, allowing applications to dynamically handle fluctuating workloads without manual intervention.
Key Point: Auto-scaling is essential for developers building cloud-native applications that need to handle variable traffic efficiently without manual oversight.
2. Types of Auto-Scaling in Google Cloud
Google Cloud offers different types of auto-scaling, each suited for specific use cases:
● Vertical Auto-Scaling: Automatically adjusts the CPU and memory of a running instance.
● Horizontal Auto-Scaling: Adds or removes instances based on traffic load.
● Scheduled Scaling: Scales resources based on a pre-defined schedule, suitable for expected traffic spikes.
● Predictive Auto-Scaling: Uses machine learning to predict future traffic and scale in advance, ensuring readiness for high demand.
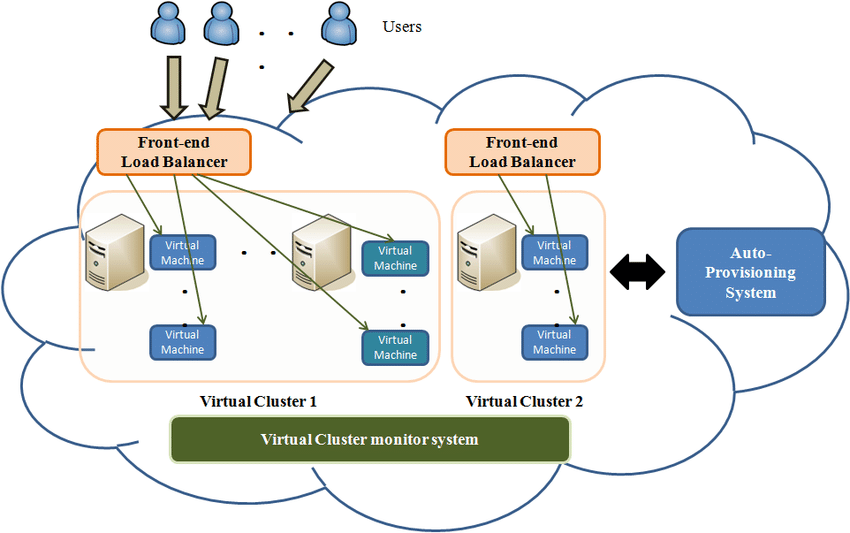
3. Setting Up Compute Engine Auto-Scaling
Google Compute Engine allows you to run virtual machines (VMs) on Google Cloud, and auto-scaling makes it easier to handle spikes in traffic. Here’s a step-by-step guide for setting up auto-scaling for a managed instance group on Compute Engine:
Step 1: Create a Managed Instance Group
A managed instance group allows Google Cloud to manage a group of VMs, automatically adding or removing instances based on load.
Go to the Google Cloud Console.
Navigate to Compute Engine → Instance Groups.
Click Create Instance Group.
Choose the option for Managed Instance Group and configure the instance template.
Step 2: Enable Auto-Scaling
In the instance group settings, select Enable Autoscaling.
Set the minimum and maximum number of instances.
Choose the Scaling Policy based on metrics like CPU usage, HTTP load balancer utilization, or custom metrics.
Click Save to activate auto-scaling.
Tip: Setting appropriate scaling limits is important. If the minimum instance count is too low, it can lead to underperformance during traffic spikes. Conversely, too high a maximum can result in unnecessary costs.
4. Kubernetes Auto-Scaling with Google Kubernetes Engine (GKE)
For developers working with microservices architecture and containers, Google Kubernetes Engine (GKE) offers seamless integration of auto-scaling features. There are two types of auto-scaling in GKE:
Horizontal Pod Auto-Scaler (HPA): Scales the number of pods in a deployment based on CPU utilization or custom metrics.
Cluster Auto-Scaler: Scales the entire Kubernetes cluster by adding or removing nodes based on the demands of the pods.
Step-by-Step: Setting Up Horizontal Pod Auto-Scaler
Here’s how to enable auto-scaling for your GKE pods:
Ensure that GKE is set up and your application is running in a Kubernetes deployment.
Set up resource requests and limits in your deployment YAML file:resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "500m"
memory: "1Gi"
Enable HPA by running the following command:
kubectl autoscale deployment <your-deployment> --cpu-percent=80 --min=1 --max=10
Verify the auto-scaler with:
kubectl get hpa
5. Real-Time Case Study: Scaling a Web Application
Let’s consider an e-commerce web application during a flash sale event. The traffic surges significantly, and without auto-scaling, the application would either crash or underperform.
Scenario:
● The application is hosted on Google Compute Engine behind a load balancer.
● Auto-scaling is configured to add instances when CPU usage exceeds 70%.
During the flash sale, the auto-scaler detects increased load and automatically adds more instances, allowing the application to handle thousands of concurrent users seamlessly. Once the traffic decreases, the auto-scaler scales down, saving costs by reducing unused resources.
6. Best Practices for Using Google Cloud Auto-Scaling
Optimize Scaling Policies
● Set graceful shutdown periods to prevent in-flight requests from being terminated abruptly during scaling down.
● Use cool-down periods to avoid scaling too frequently, which can lead to resource thrashing.
Right-Size Your Instances
Choose appropriate machine types for your instances to avoid over-provisioning, which leads to unnecessary costs.
Monitor Custom Metrics
While CPU and memory utilization are common metrics, leveraging custom metrics (like request latency) allows for more precise scaling.
7. Monitoring and Alerts: Staying in Control
Google Cloud Monitoring provides robust tools to track the performance of your application. Monitoring ensures that auto-scaling is working as intended, and it can help you adjust your scaling policies based on historical data.
Setting Up Alerts
Go to Google Cloud Console and navigate to Monitoring.
Create an alert policy based on metrics like CPU utilization or HTTP load balancer response time.
Configure notifications via email, SMS, or Slack.
This ensures you’re notified when the application experiences high traffic or resource bottlenecks, allowing you to proactively manage the scaling process.
8. Conclusion and Next Steps
Scaling your applications dynamically with Google Cloud’s Auto-Scaling features offers flexibility, cost efficiency, and resilience. Whether you're managing VMs with Compute Engine or running containerized applications on GKE, leveraging auto-scaling ensures your application stays responsive under fluctuating workloads.
As a developer, understanding the types of auto-scaling and best practices will allow you to build cloud-native applications that are cost-effective and performant.
Key Takeaways:
● Use horizontal auto-scaling for scaling across multiple instances or pods.
● Consider predictive scaling if you have regular traffic patterns.
● Always monitor your application’s performance and adjust your auto-scaling policies based on real-time data.
References
Disclaimer
This blog is intended for educational purposes only. The information provided is based on public documentation and real-time use cases. Always refer to the official Google Cloud documentation for the most up-to-date information.
Comments